CAS和原子类
9、CAS
是什么
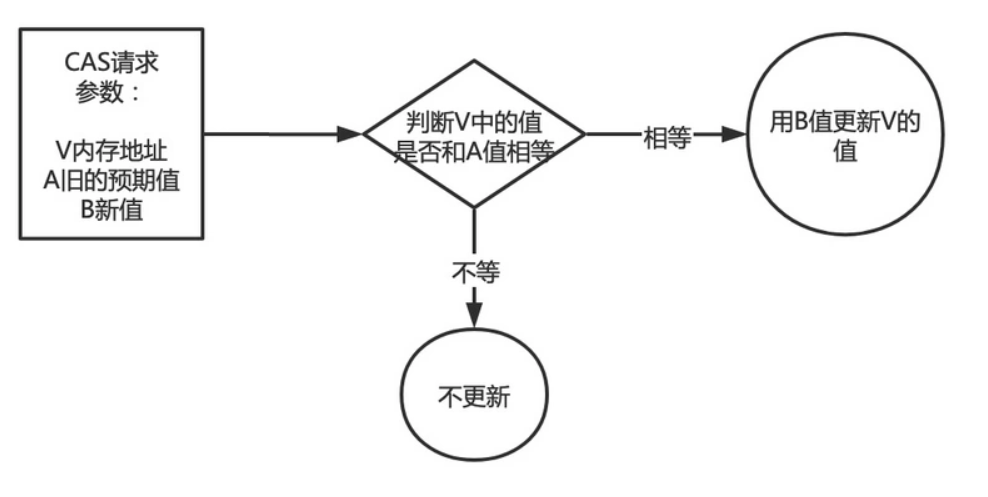
compare and swap的缩写,中文翻译成比较并交换,实现并发算法时常用到的一种技术。它包含三个操作数——内存位置、预期原值及更新值。
执行CAS操作的时候,将内存位置的值与预期原值比较:
如果相匹配,那么处理器会自动将该位置值更新为新值,
如果不匹配,处理器不做任何操作,多个线程同时执行CAS操作只有一个会成功。
硬件级别的保证
CAS是JDK提供的非阻塞原子性操作,它通过硬件保证了比较-更新的原子性。
它是非阻塞的且自身原子性,也就是说效率更高且通过硬件保证,说明这玩意更可靠。
CAS是一条CPU的原子指令(cmpxchg指令),不会造成所谓的数据不一致问题,Unsafe提供的CAS方法(如compareAndSwapXXX)底层实现即为CPU指令cmpxchg。
执行cmpxchg指令的时候,会判断当前系统是否为多核系统,如果是就给总线加锁,只有一个线程会对总线加锁成功,加锁成功之后会执行CAS操作,也就是说CAS的原子性实际上是CPU实现的, 其实在这一点上还是有排他锁的,只是比起用synchronized, 这里的排他时间要短的多, 所以在多线程情况下性能会比较好。
9.1、谈谈Unsafe魔法类中的CAS
由于Java方法无法直接访问底层系统,需要通过本地(native)方法来访问,Unsafe相当于一个后门,基于该类可以直接操作特定内存的数据。Unsafe类存在于sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存,因为Java中CAS操作的执行依赖于Unsafe类的方法。
注意Unsafe类中的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务
atomicInteger.getAndIncrement()如何保证i++的线程安全性?
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
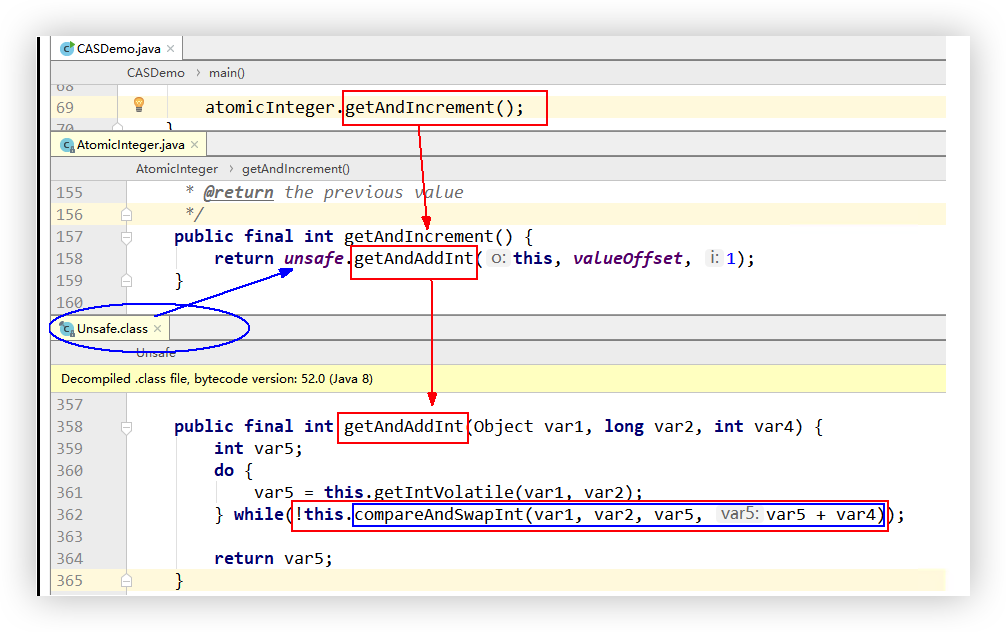
CAS并发原语体现在JAVA语言中就是sun.misc.Unsafe类中的各个方法。调用UnSafe类中的CAS方法,JVM会帮我们实现出CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。
AtomicInteger.getAndIncrement()中的具体执行流程:
AtomicInteger源码:
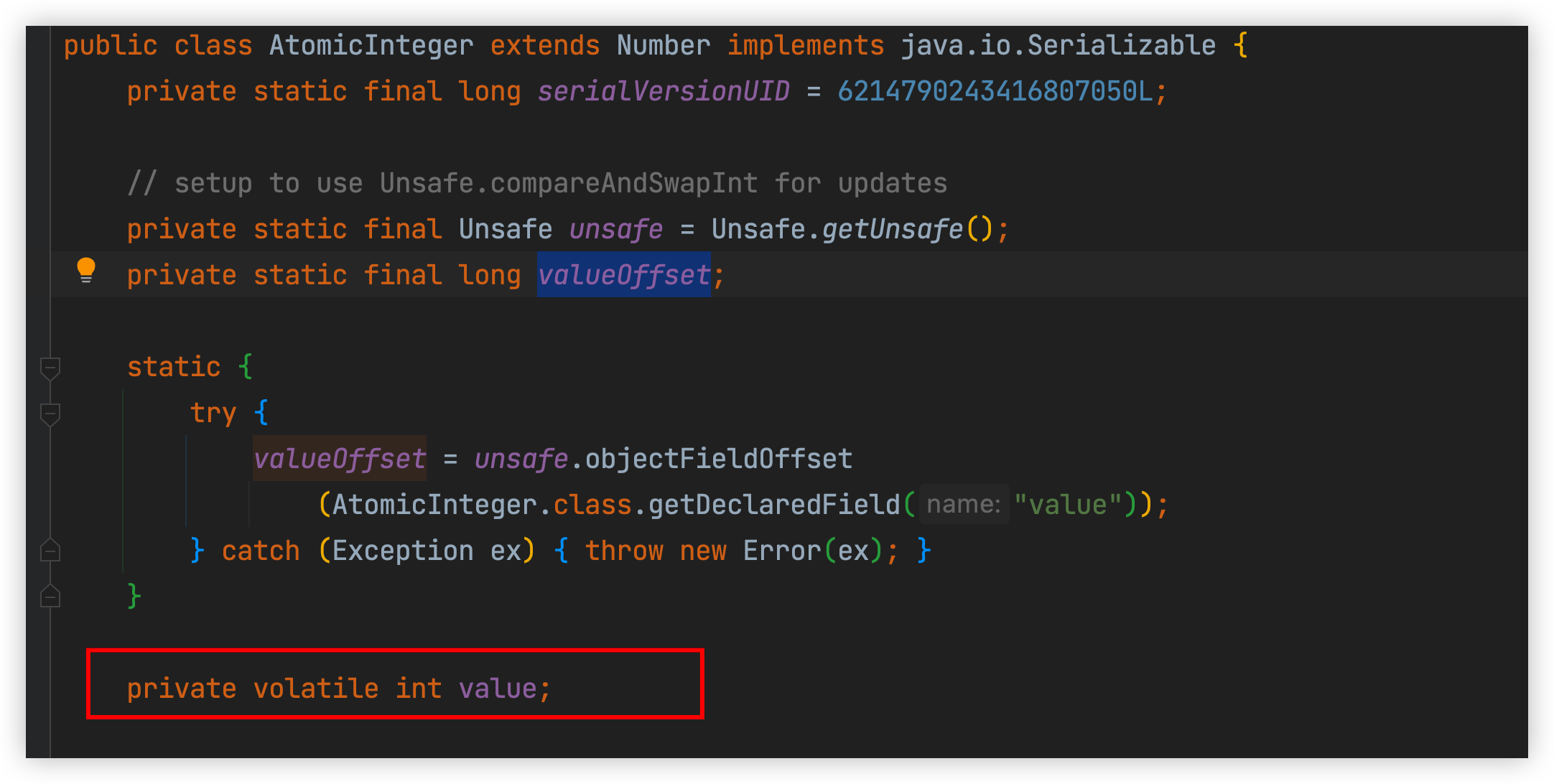
getAndIncrement()源码,最终是调用Unsafe的compareAndSwapInt方法:
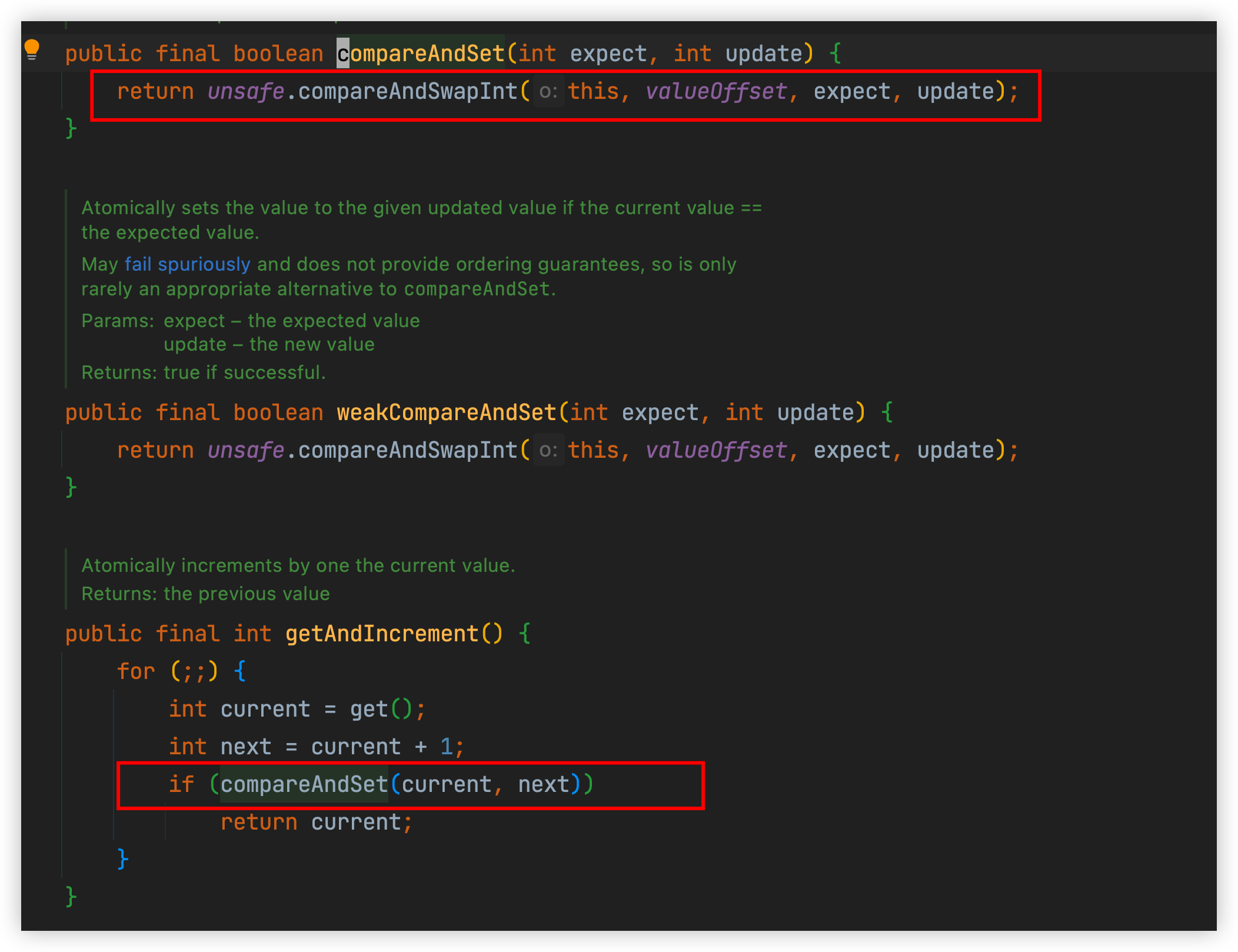
Unsafe类的compareAndSwapInt则是调用本地方法:
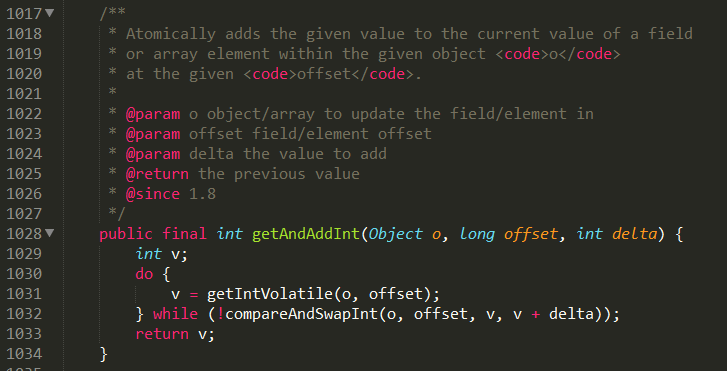
假设线程A和线程B两个线程同时执行getAndAddInt操作(分别跑在不同CPU上):
1 AtomicInteger里面的value原始值为3,即主内存中AtomicInteger的value为3,根据JMM模型,线程A和线程B各自持有一份值为3的value的副本分别到各自的工作内存。
2 线程A通过getIntVolatile(var1, var2)拿到value值3,这时线程A被挂起。
3 线程B也通过getIntVolatile(var1, var2)方法获取到value值3,此时刚好线程B没有被挂起并执行compareAndSwapInt方法比较内存值也为3,成功修改内存值为4,线程B打完收工,一切OK。
4 这时线程A恢复,执行compareAndSwapInt方法比较,发现自己手里的值数字3和主内存的值数字4不一致,说明该值已经被其它线程抢先一步修改过了,那A线程本次修改失败,只能重新读取重新来一遍了。
5 线程A重新获取value值,因为变量value被volatile修饰,所以其它线程对它的修改,线程A总是能够看到,线程A继续执行compareAndSwapInt进行比较替换,直到成功。
关于Unsafe下compareAndSwapInt的底层分析
Unsafe类对应的JVM的cpp文件为unsafe.cpp,其中就有本地方法的实现:

图片上的第四行:拿到变量value在内存中的地址,根据偏移量valueOffset,计算 value 的地址
第五行:调用 Atomic 中的函数 cmpxchg来进行比较交换,其中参数x是即将更新的值,参数e是原内存的值,Atomic.cmpxchg在不同架构的系统中实现不一样,以linux_x86为例,源码文件位于openjdk-8-source/hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)" // cmpxchgl指令用于比较dest地址中的值与compare_value是否相等,如果相等,则将exchange_value写入该地址,并将原来的值(*dest)返回;否则不进行任何操作,直接返回当前值(*dest)。
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
对以上内联汇编代码的解释:
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
这一行是内联汇编的开始,其中volatile关键字表示编译器不会在编译时对这段代码进行优化。这一行使用了x86处理器的cmpxchg指令来执行一个原子比较交换操作,如果系统是多处理器环境,则在指令前加上LOCK前缀以确保操作的原子性。具体来说,%4表示第5个输入参数mp,而LOCK_IF_MP则是一个宏定义,在多处理器环境下会被展开为"lock;",否则为空字符串。
: "=a" (exchange_value)
这一行是输出操作数的约束,表示将eax寄存器的值(即exchange_value变量)作为输出,并将其返回值保存到C语言变量exchange_value中。=a表示eax寄存器用于输出,并且是一个只写变量,即不能用于输入和修改。
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
这一行是输入操作数的约束,分别对应cmpxchg指令中的%1、%2、%3和%4。其中r表示通用寄存器或内存位置,并让编译器自行选择可用的寄存器或内存位置。
: "cc", "memory");
这一行是对代码中可能出现的条件码(condition code)和内存访问进行约束。cc表示条件码可能被修改,而memory表示该指令会访问内存,因此编译器需要保证该指令执行时所需的内存数据已经加载到寄存器或缓存中,并且在该指令执行后要将结果写回内存或缓存中。
CAS小总结:
CAS是靠硬件实现的从而在硬件层面提升效率,最底层还是交给硬件来保证原子性和可见性,实现方式是基于硬件平台的汇编指令,在intel的CPU中(X86机器上),使用的是汇编指令cmpxchg指令。
核心思想就是:比较要更新变量的值V和预期值E(compare),相等才会将V的值设为新值N(swap)如果不相等自旋再来。
10、原子操作类
10.1、基本类型原子类
- AtomicInteger
- AtomicBoolean
- AtomicLong
常用API:
public final int get() //获取当前的值
public final int getAndSet(int newValue)//获取当前的值,并设置新的值
public final int getAndIncrement()//获取当前的值,并自增
public final int getAndDecrement() //获取当前的值,并自减
public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
使用例子:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(100);
MyNumber myNumber = new MyNumber();
for (int i = 0; i < 100; i++) {
new Thread(() -> {
myNumber.add();
countDownLatch.countDown();
}, "t" + i).start();
}
countDownLatch.await();
System.out.println("total: " + myNumber.getAtomicInteger().get());
}
}
class MyNumber {
private final AtomicInteger atomicInteger = new AtomicInteger();
public AtomicInteger getAtomicInteger() {
return atomicInteger;
}
public void add() {
atomicInteger.incrementAndGet();
}
}
10.2、数组类型原子类
- AtomicIntegerArray
- AtomicLongArray
- AtomicRefrenceArray
使用例子:
import java.util.concurrent.atomic.AtomicIntegerArray;
public class AtomicIntegerArrayDemo {
public static void main(String[] args) {
AtomicIntegerArray array = new AtomicIntegerArray(new int[5]);
for (int i = 0; i < array.length(); i++) {
System.out.println("current i: " + i + ", v: " + array.get(i));
}
int r = array.getAndSet(0, 1);
System.out.println(r);
int rr= array.incrementAndGet(0);
System.out.println(rr);
}
}
10.3、引用类型原子类
-
AtomicReference
使用例子:
// 通过AtomicReference来实现单例模式 import java.util.concurrent.atomic.AtomicReference; public class AtomicReferenceSingletonDemo { private static final AtomicReference<Object> INSTANCE = new AtomicReference<>(); private AtomicReferenceSingletonDemo() {} public static Object getInstance() { for (;;) { Object o = INSTANCE.get(); if (o != null) { return o; } o = new AtomicReferenceSingletonDemo(); if (INSTANCE.compareAndSet(null, o)) { return o; } } } } -
AtomicStampedReference
携带版本号的引用类型原子类,可以解决ABA问题
import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.atomic.AtomicStampedReference; /** * @Description: 通过AtomicStampedReference解决ABA问题 * @Author: xuhao * @Date: 2023/4/4 16:07 */ public class AtomicStampedReferenceFixAbaProblemDemo { static AtomicInteger atomicInteger = new AtomicInteger(100); static AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<>(100, 1); public static void abaIssue() { new Thread(() -> { atomicInteger.compareAndSet(100, 101); atomicInteger.compareAndSet(101, 100); }, "t1").start(); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } new Thread(() -> { atomicInteger.compareAndSet(100, 0); }, "t2").start(); System.out.println("current atomicInteger value " + atomicInteger.get()); } public static void resolveAbaIssue() { new Thread(() -> { int stamp = atomicStampedReference.getStamp(); System.out.println("t3初次进来stamp为:" + stamp); atomicStampedReference.compareAndSet(100, 101, stamp, stamp + 1); System.out.println("t3经过一次compareAndSet后stamp为:" + atomicStampedReference.getStamp()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } // 改回来 atomicStampedReference.compareAndSet(101, 100, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1); System.out.println("t3改过一次后在改回来stamp为:" + atomicStampedReference.getStamp()); }, "t3").start(); new Thread(() -> { int stamp = atomicStampedReference.getStamp(); System.out.println("t4初次进来stamp为:" + stamp); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } boolean result = atomicStampedReference.compareAndSet(100, 9999, stamp, stamp + 1); System.out.println("t4我期望引用数据是100,我要改为9999,是否修改成功呢:" + result + ", 当前的数据是:" + atomicStampedReference.getReference() + ", 我期望stamp为:" + stamp + " 当前stamp: " + atomicStampedReference.getStamp()); }, "t4").start(); } public static void main(String[] args) { abaIssue(); resolveAbaIssue(); } } -
AtomicMarkableReference
原子更新带有标记位的引用类型对象,它的定义就是相当于将上面的AtomicStampedRefefrence的状态戳简化为true|false
import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicMarkableReference; public class AtomicMarkableReferenceDemo { static AtomicMarkableReference<Integer> markableReference = new AtomicMarkableReference<>(100, false); public static void main(String[] args) { System.out.println("============AtomicMarkableReference不关心引用变量更改过几次,只关心是否更改过======================"); new Thread(() -> { boolean marked = markableReference.isMarked(); System.out.println(Thread.currentThread().getName() + "\t 1次版本号" + marked); try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } markableReference.compareAndSet(100, 101, marked, !marked); System.out.println(Thread.currentThread().getName() + "\t 2次版本号" + markableReference.isMarked()); markableReference.compareAndSet(101, 100, markableReference.isMarked(), !markableReference.isMarked()); System.out.println(Thread.currentThread().getName() + "\t 3次版本号" + markableReference.isMarked()); }, "t5").start(); new Thread(() -> { boolean marked = markableReference.isMarked(); System.out.println(Thread.currentThread().getName() + "\t 1次版本号" + marked); //暂停几秒钟线程 try { TimeUnit.MILLISECONDS.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } markableReference.compareAndSet(100, 2023, marked, !marked); System.out.println(Thread.currentThread().getName() + "\t" + markableReference.getReference() + "\t" + markableReference.isMarked()); }, "t6").start(); } }
10.4、对象属性修改的原子类
用途说明:
以一种线程安全的方式操作非线程安全对象内的某些字段,更新的对象属性必须使用 public volatile 修饰符,保证多线程环境下的线程可见性。
因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
-
AtomicIntegerFieldUpdater
原子更新对象中int类型字段的值
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater; public class AtomicIntegerFieldUpdaterDemo { public static void main(String[] args) { Account account = new Account(); account.setName("ABC"); for (int i = 0; i < 1000; i++) { new Thread(() -> account.transfer(account), "t" + i).start(); } try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("account " + account.getName() + ", current money : " + account.getMoney()); } } class Account { private String name; private volatile int money = 0; static final AtomicIntegerFieldUpdater<Account> atomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Account.class, "money"); public String getName() { return name; } public void setName(String name) { this.name = name; } public int getMoney() { return money; } public void setMoney(int money) { this.money = money; } public void transfer(Account account) { atomicIntegerFieldUpdater.incrementAndGet(account); } } -
AtomicLongFieldUpdater
原子更新对象中Long类型字段的值
-
AtomicReferenceFieldUpdater
原子更新引用类型字段的值
import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicReferenceFieldUpdater; public class AtomicReferenceFieldUpdaterDemo { public static void main(String[] args) { Phone phone = new Phone(); for (int i = 0; i < 5; i++) { new Thread(() -> { phone.init(phone); }, String.valueOf(i)).start(); } } } class Phone { private volatile Boolean supportEsim = Boolean.FALSE; static final AtomicReferenceFieldUpdater<Phone, Boolean> atomicReferenceFieldUpdater = AtomicReferenceFieldUpdater.newUpdater(Phone.class, Boolean.class, "supportEsim"); public void init(Phone phone) { // 设置phone支持esim功能 if (atomicReferenceFieldUpdater.compareAndSet(phone, Boolean.FALSE, Boolean.TRUE)) { System.out.println(Thread.currentThread().getName()+"\t"+"---init....."); //暂停几秒钟线程 try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+"\t"+"---init.....over"); } else { System.out.println(Thread.currentThread().getName()+"\t"+"------其它线程正在初始化"); } } }
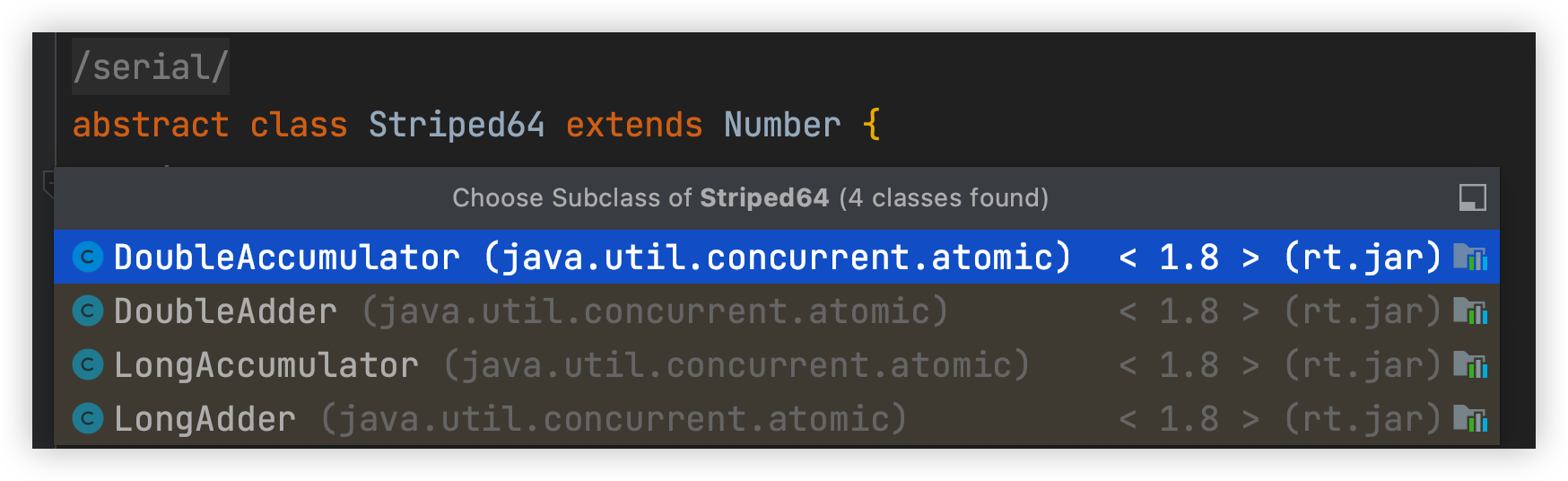
10.5、原子操作增强类原理解析
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
通过下面的图可以看出上面的4大天王都是JDK1.8新增的,它们都继承了Striped64这个核心抽象类,而大部分的核心逻辑都是在这个Striped64中实现的。
10.5.1 Striped64重要属性及方法
/** CPU的数量,也是cells数组的最大长度 */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* cells数据,每次扩容的大小为2的幂次方,最大为CPU的数量
*/
transient volatile Cell[] cells;
/**
* 基础value值,在并发不激烈的时候通过CAS累加该值
*/
transient volatile long base;
/**
* 自旋锁,通过CAS上锁。在初始化cells数组或者cells数组扩容的时候使用
*/
transient volatile int cellsBusy;

10.5.1.1、Cell
Cell是Striped64 的一个内部类,cells数组中存放的就是它。可以从下图看到里面有个volatile修饰的value,出现了竞争后就是来累加这些Cell中的value值(通过CAS),而后如果要获取整个LongAdder值那么就是所有Cell中的value + base,因为在统计的时候可能还会有线程在进行累加,所以LongAdder只能取到近似值。如下方的第2张图中的逻辑可见。
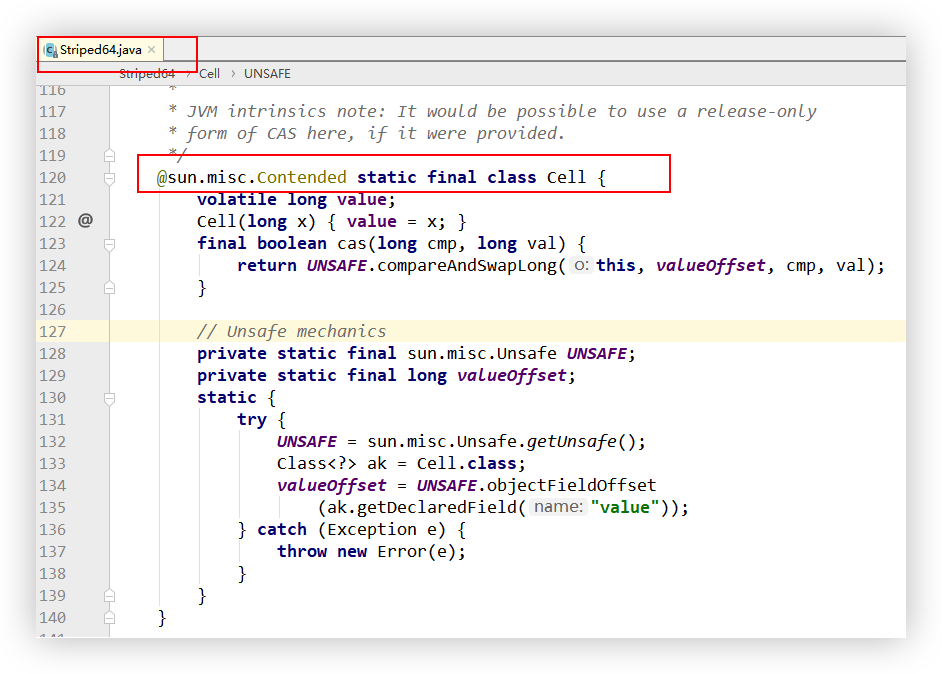
LongAdder sum进行取值。
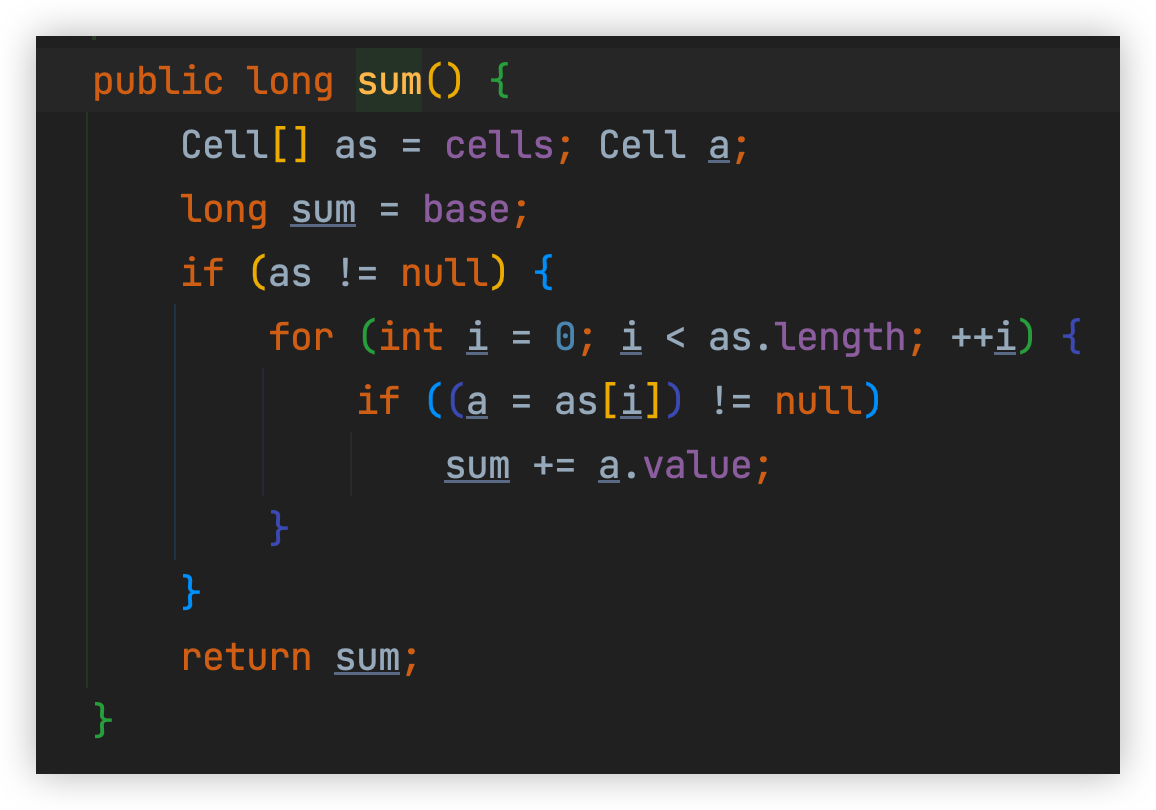
上方第一个图中Cell类上面有一个@sun.misc.Contented注解,这个注解使用来进行字节填充的,为了解决伪共享问题。
10.5.1.2 ‼️那么什么是伪共享呢(false-sharing)?
因为在计算机中,CPU的运行速度肯定是要比内存快的,每次的数据交互CPU不可能等待内存的读取或者写入操作,那样会大大降低系统的响应速度,为了解决这个问题就引入了高速缓存,以我们常见的X86系列的windows系统的计算机来说,一般都会有3级高速缓存,在任务管理器中可以看见L1,L2,L3等,数字越小的越接近CPU但是容量就更小,而缓存行又是处理器中缓存的基本单位,常见的X86 64位的系统一般缓存行的大小都是64字节。
以上面的Cell类为例,如果某一时刻LongAdder有2个Cell(起名为c1,c2),此时如果这2个Cell的大小刚好不超过一个缓存行的大小64字节,那么这2个Cell就会被放入到同一个缓存行,由于缓存行是操作CPU缓存的基本单位,那么当在操作c1时因为缓存一致性协议(MESI)同一时间只能一个线程操作该缓存行,那么如果其它线程此时想要对c2进行累加操作那么就得等着c1对该缓存行操作结束并将数据写回主内存,且此时另外一个线程操作c2还要重新去从主内存中读取变量才能进行操作,可见这是非常耗时的,看似每个线程内存都有一份,可以各玩各的但是还是得等,这就是伪共享问题,为了解决这个问题就是要将这些变量放到不同的缓存行即可,那能想到的办法就是字节填充!
JDK1.8之前的字节填充可以通过补充辅助变量的方式:
static final class PaddedLongField {
public volatile long value = 0L;
public long p1,p2,p3,p4,p5;
}
7个long类型的变量大小为6*8=48,加上PaddedLongField对象头的长度16个字节,刚好64个字节,独占一个缓存行。(⚠️我这是基于X86 64位linux系统得出的,在我的mac上它的缓存行大小为128字节,所以这玩意要依据实际情况来计算)
而在JDK1.8及以后就可以使用@sun.misc.Contented来填充对齐,需要注意,@Contended注解默认只用于Java核心类,比如rt.jar下的类。如果我们应用程序中想使用这个注解,
需要添加一个JVM参数:-XX:-RestrictContended,填充的默认宽度为128字节,若需自定义宽度则可以用另一个参数:-XX:ContendedPaddingWidth=xxx
空口无凭,下面是对有填充和没有填充的类在多线程环境下的操作通过JMH进行的测试。
import sun.misc.Contended;
/**
* @Description: 有填充的类
* @Author: xuhao
* @Date: 2023/4/12 14:52
*/
@Contended
public class PaddingClz {
public long value = 0;
public long b = 0;
}
/**
* @Description: 无填充的类
* @Author: xuhao
* @Date: 2023/4/12 14:53
*/
public class UnPaddingClz {
public long value = 0;
public long b = 0;
}
/**
* @Description: 测试类
* @Author: xuhao
* @Date: 2023/4/12 14:49
*/
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Fork(value = 1, jvmArgsPrepend = "-XX:-RestrictContended")
@Warmup(iterations = 5)
@Measurement(iterations = 10)
@Threads(4)
public class CacheLineBenchMarkTest {
private PaddingClz pc = new PaddingClz();
private UnPaddingClz upc = new UnPaddingClz();
@Group("padding")
@GroupThreads(2)
@Benchmark
public void paddingAddV() {
pc.value ++;
}
@Group("padding")
@GroupThreads(2)
@Benchmark
public void paddingAddB() {
pc.b ++;
}
@Group("nopadding")
@GroupThreads(2)
@Benchmark
public void unPaddingAddV() {
upc.value ++;
}
@Group("nopadding")
@GroupThreads(2)
@Benchmark
public void unPaddingAddB() {
upc.b ++;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(CacheLineBenchMarkTest.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
得到的结果:
Benchmark Mode Cnt Score Error Units
CacheLineBenchMarkTest.nopadding avgt 10 2.513 ± 0.085 ns/op
CacheLineBenchMarkTest.nopadding:unPaddingAddB avgt 10 2.513 ± 0.080 ns/op
CacheLineBenchMarkTest.nopadding:unPaddingAddV avgt 10 2.513 ± 0.095 ns/op
CacheLineBenchMarkTest.padding avgt 10 6.233 ± 0.520 ns/op
CacheLineBenchMarkTest.padding:paddingAddB avgt 10 6.266 ± 1.149 ns/op
CacheLineBenchMarkTest.padding:paddingAddV avgt 10 6.201 ± 0.936 ns/op
可以清楚的看到有填充的比没有填充的在多线程的环境下效率是要高的,虽然占用了更多的缓存行空间但是换来了时间。
10.5.2、浅说LongAdder
经过了上面一系列的铺垫。其实LongAdder的基本原理已经浮现了,LongAdder在无竞争的情况,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用化整为零的做法,从空间换时间,用一个数组cells,将一个value拆分进这个数组cells。
多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和无竞争值base都加起来作为最终结果。
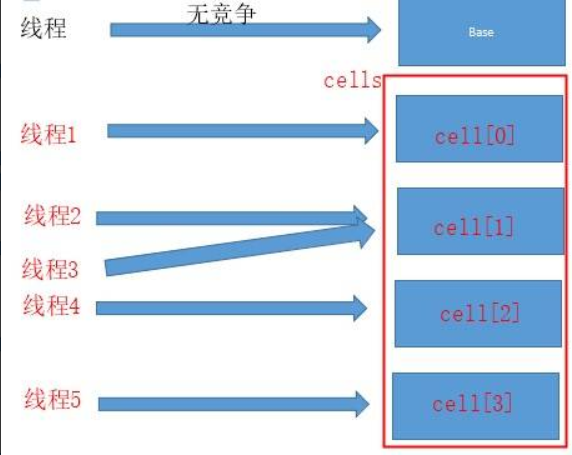

分析一哈add方法源码
public void add(long x) {
// as是当前LongAdder中的cells数组
// b是base的值
// v是在as中取出的cell对象的value
// m是as数组的长度-1,其实也就对应着as数组的最大下标
// a就是取到的Cell对象
Cell[] as; long b, v; int m; Cell a;
// 两种情况:
// 1、未发生竞争此时as == null,那么就对base进行CAS操作进行累加,如果CAS成功那么本次累加结束。
// 2、如果as不为空,出现过竞争,cells数组已经创建
if ((as = cells) != null || !casBase(b = base, b + x)) {
//true为未出现竞争(指的是对随机取的cell中的value进行累加时),false时表示多个线程同时hash到了这个cell,可能需要扩容
boolean uncontended = true;
// 1、如果as==null成立说明是从上方if的第2个条件进入的,表明对base出现了竞争
// 2、看Striped64的源码就知道这个m应该是不会小于0的,初始化了就会有2个cell
// 3、hash到的cell对象为null,说明还没有更新该cell,需要进行Cell初始化
// 4、对hash到的Cell的value进行CAS操作,更新成功说明没出现竞争,否则反之。
if (as == null || (m = as.length - 1) < 0 ||
// getProbe()是取当前线程中threadLocalRandomProbe,同一个线程中该值一般是固定的(除非被修改)
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
// 进入Striped64中进行下一步的处理
longAccumulate(x, null, uncontended);
}
}
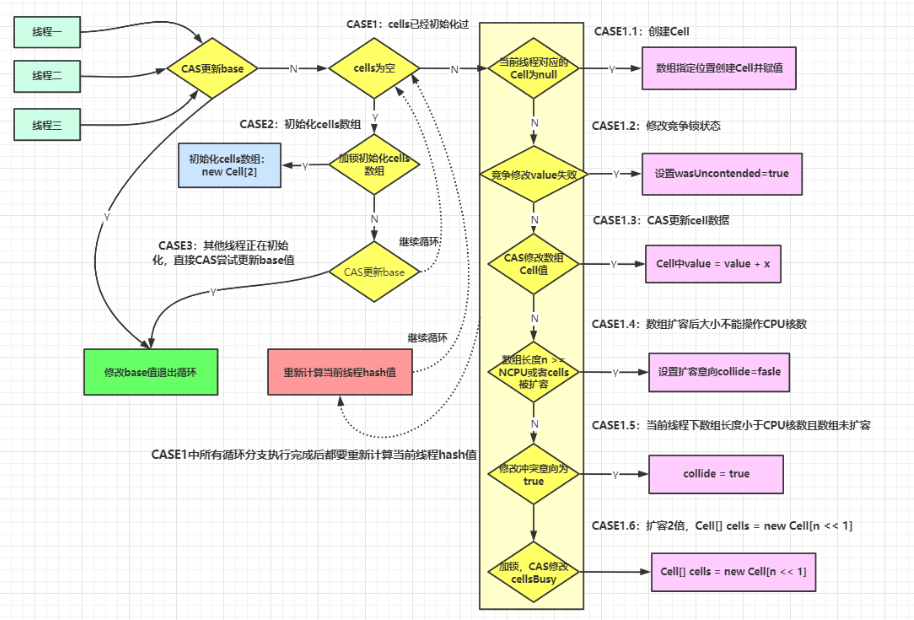
Striped64的longAccumulate方法源码分析
其实这块应该放在上方的10.5.1中,但是LongAdder继承了它,放在这也无伤大雅。
// x是要累加的值
// fn 更新函数,默认传入的就是null
// wasUncontended false的是否表示有竞争,只有cells数组初始化后且对Cell的value进行CAS时失败才会为false
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h; // 可以认为这是当前线程的一个hash码,初始值为0
if ((h = getProbe()) == 0) { // 获得hash,如果是0代表未初始化
ThreadLocalRandom.current(); // 强制初始化当前线程的hash
h = getProbe(); // 再次获取初始化后的hash
wasUncontended = true; // 说明当前线程没有竞争过,如果有竞争早就初始化hash了
}
boolean collide = false; // // True if last slot nonempty
for (;;) {
// as是cells数组
// a是通过cells的当前长度与上线程hash得到的一个下标所在位置的Cell
// n是cells的长度
// v是a这个Cell中的value
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) { // cells数组已经初始化过了,发生过base竞争了
if ((a = as[(n - 1) & h]) == null) { // 如果通过当前线程取出的Cell为空,当前位置的Cell还未创建
if (cellsBusy == 0) { // 当前cells数组是否空闲,空闲则创建这个Cell
Cell r = new Cell(x); // 创建Cell
if (cellsBusy == 0 && casCellsBusy()) { // 再次判断cells是否空闲如果空闲则通过CAS把cells状态置为繁忙
boolean created = false; // Cell添加进cells成功标志
try { // Recheck under lock
Cell[] rs; int m, j;
// 判断cells数组已经初始化了
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
// 计算cells长度 与 当前线程hash得到所对应的Cell在这个cells中的下标
// 只有该下标下的Cell为null才放入刚才新建Cell
// 因为在上次判断到这次判断Cell对象为空之间可能会有其它线程已经初始化了当前位置的Cell,
// 所有本线程占用cellsBusy锁之后需要再次判断
rs[j = (m - 1) & h] == null) {
// 把新建的Cell放入
rs[j] = r;
// 设置放入成功标志
created = true;
}
} finally {
// 释放锁
cellsBusy = 0;
}
// 新建Cell并放入成功则本次longAccumulate调用结束
if (created)
break;
continue; // 本线程计算得到的cells中的插槽在准备新建插入的过程中被其它线程占用且初始化了不为空,继续循环走下面的逻辑
}
}
collide = false; // 设置碰撞状态为false,这个是指线程
}
else if (!wasUncontended) // 是因为发生过竞争且失败了才进入的本方法
wasUncontended = true; // 设置当前线程没有发生竞争,然后到下方的advanceProbe(h)重新rehash重新循环
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x)))) // 到这块说明本线程对应的Cell已经存在,对value开始CAS累加
break; // 累加成功,本次调用结束
else if (n >= NCPU || cells != as) // cells的长度大于等于当前规定的最大长度(CPU的个数),as被其它线程修改了都不可再扩容,重新rehash算index
collide = false; // 还能修改as也就是添加Cell说明未发生碰撞
else if (!collide) // 能走到这来,说明对本线程对应的Cell的value进行CAS失败
collide = true; // 标记为发生了碰撞,给出扩容意向。重新rehash
else if (cellsBusy == 0 && casCellsBusy()) { // 如果能拿到锁就干下面的扩容操作
try {
if (cells == as) { // 如果as没被其它线程改过
Cell[] rs = new Cell[n << 1]; // 扩容为原来大小的2倍
for (int i = 0; i < n; ++i) // 拷贝老数组的元素到新数组
rs[i] = as[i];
cells = rs; // 把扩容后的新数组的赋值给cells
}
} finally {
cellsBusy = 0; // 释放锁
}
collide = false; // 设置碰撞状态为false,重置扩容意向相当于
continue; // 在扩容数组的基础上进行尝试再次累加
}
h = advanceProbe(h); // 重新算一个当前线程的hash
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) { // 初次进入cells数组为null,尝试拿锁并且初始化cells
boolean init = false; //
try { // 初始化cells
if (cells == as) { // 如果在拿到锁之前没被其它线程抢先一步初始化就进行下面流程
Cell[] rs = new Cell[2]; // 默认初始化的cells大小为2
rs[h & 1] = new Cell(x); // 1 = rs.length() - 1, 算出当前线程对应的下标,新建一个Cell丢入该下标位置
cells = rs; // 赋值给cells
init = true; // 初始化成功
}
} finally {
cellsBusy = 0; // 释放锁
}
if (init)
break; // 初始化成功则退出本次调用
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x)))) // 兜底方案,上面的几次跳出机会都没轮到那就在base上CAS累加直到成功后结束本次调用
break;
}
}
longAccumulate流程图如下:
10.5.3、AtomicLong和LongAdder比较
AtomicLong可以保证获取到的计数的精度,但是因为其内部是对单个base进行CAS,所以高并发的时候会出现激烈竞争,不停的失败重试失败重试产生大量自旋,导致性能损耗。
而LongAdder采用了分散热点,分而治之的办法,在原有的base的基础上又添加了cells数组,将对base的冲击分散到了各个Cell上,减少了CAS等待时间,效率大大提高;但其缺点就是多线程环境下取值无法保证精确,单线程下和AtomicLong无异。